【記事の目標】
Pandasを利用してデータ分析(表連結)してみよう。
【作業手順】
1.Pandasをインストール
2.Pandasをインポート
3.テストデータを作成して読み込もう
4.表を結合してみよう
5.同じ値のみを抽出してみよう
1.Pandasをインストール
以下記事の「1.」と「2.」の手順で実施しましょう。
【Python】【14】Pandasを利用して表を表示してみよう
2.Pandasをインポート
以下のようにインポートしましょう。
import pandas as pd
これで、Pandasが利用できるようになりました。
3.テストデータを作成して読み込もう
今回は表結合に利用するデータを定義していきます。
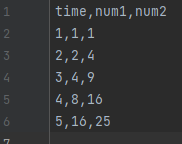
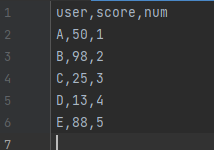
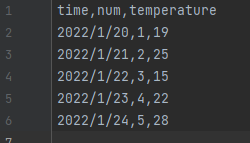
以下のように、2つの表データを設定してみましょう。


1つ目のファイルを「blog_test_5.csv」、2つ目のファイルを「blog_test_6.csv」で保存しましょう。
私の場合は以下のように保存しています。
では、この2つのファイルを読み込みましょう。
data1 = pd.read_csv('./csv/blog_test_5.csv', index_col='time')
data2 = pd.read_csv('./csv/blog_test_6.csv', index_col='time')
index_col を指定して読み込ませます。
4.表を結合してみよう
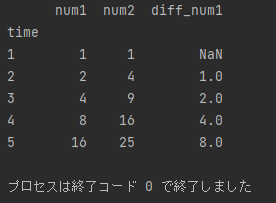
では、読み込んだデータ同士を結合してみましょう。
concat_data = pd.concat([data1, data2])
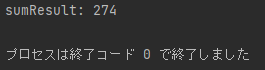
print(concat_data)
結合する場合は、pandas の concat() を利用します。
concat() の引数に結合したい表を配列で渡すことで表を結合してくれます。
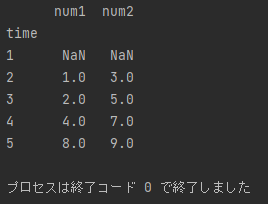
では、実行してみましょう。
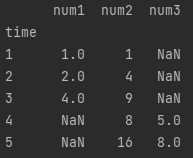
2つの表が結合されていますね。
同じ列名の部分は綺麗に表示されていて、結合したときにデータが存在しない部分は NaN で表示されています。
5.同じ行のみを抽出してみよう
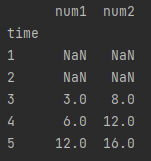
「3.」で作成した、「blog_test_6.csv」のデータを以下に書き換えましょう。
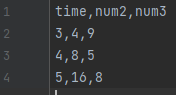
同じ行というのはインデックスが同じという意味になります。
なので、今回は time の列をインデックスに指定しているため、書き換えたことにより、どちらのファイルにも time が 3 の行が設定されていることになります。
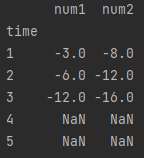
では、修正したデータを読み込んで同じ行のみを抽出してみましょう。
merge_data = pd.merge(data1, data2)
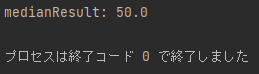
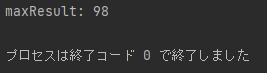
print(merge_data)
同じ行のみを抽出する場合は、pandas の merge() を利用します。
merge() の引数に2つのデータを渡すことで、同じ行を抽出してくれます。
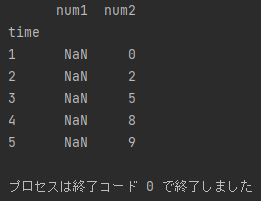
では、実行してみましょう。
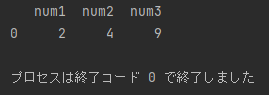
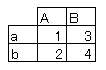
・「blog_test_5.csv」の time が 3 の num1 は 2 、num2 は 4、num3 は未定義
・「blog_test_6.csv」の time が 3 の num1 は未定義 、num2 は 4、num3 は 9
time が 3 のデータのみ抽出できていますね。
今回も引き続き Pandas を利用しています。
入り口部分の簡単なところだけ記事にしていますが、応用していくと様々な分析ができるようになっています。